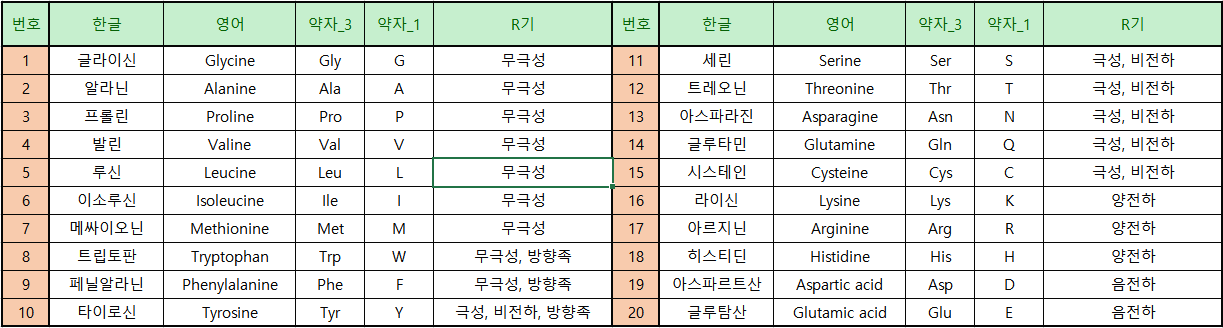
전역 변수 및 함수 선언
프로그램 전체에서 사용될 전역 변수 및 함수를 선언한다. 세 가지 배열을 이용해 코돈표를 저장하고, 서열을 저장하기 위한 구조체 배열과 본문에서 사용할 두 함수를 선언한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
|
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
// 배열 및 구조체 선언부
char codon_table_1[4][4][4][4] = {
{ {"UUU", "UUC", "UUA", "UUG"}, {"UCU", "UCC", "UCA", "UCG"}, {"UAU", "UAC", "UAA", "UAG"}, {"UGU", "UGC", "UGA", "UGG"} },
{ {"CUU", "CUC", "CUA", "CUG"}, {"CCU", "CCC", "CCA", "CCG"}, {"CAU", "CAC", "CAA", "CAG"}, {"CGU", "CGC", "CGA", "CGG"} },
{ {"AUU", "AUC", "AUA", "AUG"}, {"ACU", "ACC", "ACA", "ACG"}, {"AAU", "AAC", "AAA", "AAG"}, {"AGU", "AGC", "AGA", "AGG"} },
{ {"GUU", "GUC", "GUA", "GUG"}, {"GCU", "GCC", "GCA", "GCG"}, {"GAU", "GAC", "GAA", "GAG"}, {"GGU", "GGC", "GGA", "GGG"} }
};
char codon_table_2[4][4][4][5] = {
{ {"F", "F", "L", "L"}, {"S", "S", "S", "S"}, {"Y", "Y", "stop", "stop"}, {"C", "C", "stop", "W"} },
{ {"L", "L", "L", "L"}, {"P", "P", "P", "P"}, {"H", "H", "Q", "Q"}, {"R", "R", "R", "R"} },
{ {"I", "I", "I", "M"}, {"T", "T", "T", "T"}, {"N", "N", "K", "K"}, {"S", "S", "R", "R"} },
{ {"V", "V", "V", "V"}, {"A", "A", "A", "A"}, {"D", "D", "E", "E"}, {"G", "G", "G", "G"} }
};
char codon_table_3[4][4][4][5] = {
{ {"Phe", "Phe", "Leu", "Leu"}, {"Ser", "Ser", "Ser", "Ser"}, {"Tyr", "Tyr", "stop", "stop"}, {"Cys", "Cys", "stop", "Trp"} },
{ {"Leu", "Leu", "Leu", "Leu"}, {"Pro", "Pro", "Pro", "Pro"}, {"His", "His", "Gln", "Gln"}, {"Arg", "Arg", "Arg", "Arg"} },
{ {"Ile", "Ile", "Ile", "Met"}, {"Thr", "Thr", "Thr", "Thr"}, {"Asn", "Asn", "Lys", "Lys"}, {"Ser", "Ser", "Arg", "Arg"} },
{ {"Val", "Val", "Val", "Val"}, {"Ala", "Ala", "Ala", "Ala"}, {"Asp", "Asp", "Glu", "Glu"}, {"Gly", "Gly", "Gly", "Gly"} }
};
struct Amino_Acid {
char Amino_seq[20000];
} AA_seq[3];
/* AA_seq[0]는 1약자
AA_seq[1]은 3약자
AA_seq[2]는 코돈 단위로 분리한 서열 */
// 전역변수 선언부
// 함수 선언부
void translation_codon( char *mRNAseq, int temp_i );
int find_AUG ( char *mRNAseq );
|
cs |
코드 설명
1~3: 헤더파일 불러오기
5~10: 코돈표 선언. 염기서열 부분
12~17: 코돈표 선언. 지정 단백질 부분. 한 글자 약자
19~24: 코돈표 선언. 지정 단백질 부분. 세 글자 약자
26~28: 단백질을 암호화하는 RNA 서열과 번역결과로 나타나는 아미노산 서열을 저장하는 구조체 배열 선언.
36~37: 함수 선언
mRNA Seq.의 번역 결과를 저장하기 위한 함수 translation_codon 작성
기존에 작성한 함수 translation_codon1에 일부 코드를 추가하여 종결코돈이 나타나면 번역을 종료하도록 코드를 작성하였다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
|
void translation_codon( char *mRNAseq, int temp_i )
{
int i=0, j; // 반복문 매개변수
int temp;
int x=10, y=10, z=10; // codon 매개변수
i=temp_i;
if(temp_i > strlen(mRNAseq) ) {
printf("Error: Not found initiation code");
exit(0);
}
/* AUG를 인식하지 않으면 번역하지 않도록 하는 키
제거해도 코드의 동작에는 오류가 없다. */
while ( i<strlen(mRNAseq) )
{
if( mRNAseq[i] != '\0' )
{
x=10, y=10, z=10;
for(j = 0; j < 3 ; j++)
{
if(mRNAseq[i] == 'U') {
temp = 0;
if(j == 0) { x = temp; }
else if(j == 1) { y = temp; }
else if(j == 2) { z = temp; }
else { printf("코드에 오류가 있습니다.\n"); }
}
else if(mRNAseq[i] == 'C') {
temp = 1;
if(j == 0) { x = temp; }
else if(j == 1) { y = temp; }
else if(j == 2) { z = temp; }
else { printf("코드에 오류가 있습니다.\n"); }
}
else if(mRNAseq[i] == 'A') {
temp = 2;
if(j == 0) { x = temp; }
else if(j == 1) { y = temp; }
else if(j == 2) { z = temp; }
else { printf("코드에 오류가 있습니다.\n"); }
}
else if(mRNAseq[i] == 'G') {
temp = 3;
if(j == 0) { x = temp; }
else if(j == 1) { y = temp; }
else if(j == 2) { z = temp; }
else { printf("코드에 오류가 있습니다.\n"); }
}
else { printf("ERORR_CODE_%d잘못된 입력입니다.\n다시 입력해주십시오.\n", i); }
i++;
}
if(x>3 || y > 3 || z > 3 ) {
printf("\nERORR_CODE_123잘못된 입력입니다.\n다시 입력해주십시오.\n");
printf("%d %d %d\n", x, y, z);
}
else if( strncmp( codon_table_2[x][y][z], "stop", 4) == 0 ) {
strcat( AA_seq[2].Amino_seq, codon_table_1[x][y][z] );
strcat( AA_seq[2].Amino_seq, " \0");
break;
}
else {
strcat( AA_seq[0].Amino_seq, codon_table_2[x][y][z] );
strcat( AA_seq[0].Amino_seq, " \0");
strcat( AA_seq[1].Amino_seq, codon_table_3[x][y][z] );
strcat( AA_seq[1].Amino_seq, " \0");
strcat( AA_seq[2].Amino_seq, codon_table_1[x][y][z] );
strcat( AA_seq[2].Amino_seq, " \0");
}
}
else { break; }
}
printf("\n");
}
|
cs |
삽입 코드: 19, 58~62
코드 설명
19: 코돈의 염기 값을 나타내는 변수 x, y, z의 값을 모두 10으로 초기화하여 오류를 방지한다.
58: 종결코돈을 인식한다. 세 변수 x, y, z의 값에 의하여 결정되는 문자열 codon_table_2[x][y][z]가 "stop"일 경우 함수 strncmp는 0을 반환하도록 한다. 그러므로 함수가 반환하는 값이 0이면 코드문 59~62를 수행한다.
59~62: 종결코돈을 번역을 수행하는 RNA 서열에 저장하고 반복문 15~73을 빠져나간다.
번역의 시작을 알려주기 위한 함수 find_AUG 작성
기존에 작성한 함수 find_AUG2를 그대로 사용하였다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
int find_AUG ( char *mRNAseq )
{
const char initiation_codon[4] = "AUG\0";
int i;
int AUG_slot = 0;
for( i=0; i<strlen(mRNAseq)+1; i++ ) {
if( mRNAseq != '\0' ) {
if( mRNAseq[i] == 'A' && mRNAseq[i+1] == 'U' && mRNAseq[i+2] == 'G' ){ return AUG_slot; }
else{ AUG_slot++; }
}
else {
return AUG_slot;
}
}
}
|
cs |
main 함수 작성
함수 translation_codon을 수정하여 종결코돈을 감지하면 번역이 종료되도록 코드를 작성하였다. 그러므로 기존에 작성한 main 함수3를 거의 수정하지 않고 사용하겠다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
main()
{
int temp_taa, temp_AUG_slot;
char mRNA_seq[10000] = "\0";
printf("입력 예시: UUU (#주의# 코돈 입력은 반드시 대문자로 해주세요.)\n");
printf("출력 예시: %c \n", codon_table_2[0][0][0][0]);
printf("U = 0, C = 1, A = 2, G = 3\n코돈 입력\n>>> ");
scanf("%s", mRNA_seq);
printf("숫자를 입력하세요\n 0 입력: 아미노산 한 글자로 출력\n 1 입력: 아미노산 세 글자로 출력\n>>> ");
scanf("%d", &temp_taa);
temp_AUG_slot = find_AUG( mRNA_seq );
translation_codon( mRNA_seq, temp_AUG_slot );
printf("mRNA Seq. 출력\n>>> %s\n", AA_seq[2].Amino_seq);
printf("translation\n>>> %s\n", AA_seq[temp_taa].Amino_seq);
return 0;
}
|
cs |
기존의 코드문 11~12를 현재의 코드문 14~15로 순서를 바꿨다. 수정 후에도 입출력에 있어서 기존과 동일한 동작을 수행한다.
현재 단계에서 작성한 코드 결과물
현재 단계에서 작성한 코드 결과물
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
// 배열 및 구조체 선언부
char codon_table_1[4][4][4][4] = {
{ {"UUU", "UUC", "UUA", "UUG"}, {"UCU", "UCC", "UCA", "UCG"}, {"UAU", "UAC", "UAA", "UAG"}, {"UGU", "UGC", "UGA", "UGG"} },
{ {"CUU", "CUC", "CUA", "CUG"}, {"CCU", "CCC", "CCA", "CCG"}, {"CAU", "CAC", "CAA", "CAG"}, {"CGU", "CGC", "CGA", "CGG"} },
{ {"AUU", "AUC", "AUA", "AUG"}, {"ACU", "ACC", "ACA", "ACG"}, {"AAU", "AAC", "AAA", "AAG"}, {"AGU", "AGC", "AGA", "AGG"} },
{ {"GUU", "GUC", "GUA", "GUG"}, {"GCU", "GCC", "GCA", "GCG"}, {"GAU", "GAC", "GAA", "GAG"}, {"GGU", "GGC", "GGA", "GGG"} }
};
char codon_table_2[4][4][4][5] = {
{ {"F", "F", "L", "L"}, {"S", "S", "S", "S"}, {"Y", "Y", "stop", "stop"}, {"C", "C", "stop", "W"} },
{ {"L", "L", "L", "L"}, {"P", "P", "P", "P"}, {"H", "H", "Q", "Q"}, {"R", "R", "R", "R"} },
{ {"I", "I", "I", "M"}, {"T", "T", "T", "T"}, {"N", "N", "K", "K"}, {"S", "S", "R", "R"} },
{ {"V", "V", "V", "V"}, {"A", "A", "A", "A"}, {"D", "D", "E", "E"}, {"G", "G", "G", "G"} }
};
char codon_table_3[4][4][4][5] = {
{ {"Phe", "Phe", "Leu", "Leu"}, {"Ser", "Ser", "Ser", "Ser"}, {"Tyr", "Tyr", "stop", "stop"}, {"Cys", "Cys", "stop", "Trp"} },
{ {"Leu", "Leu", "Leu", "Leu"}, {"Pro", "Pro", "Pro", "Pro"}, {"His", "His", "Gln", "Gln"}, {"Arg", "Arg", "Arg", "Arg"} },
{ {"Ile", "Ile", "Ile", "Met"}, {"Thr", "Thr", "Thr", "Thr"}, {"Asn", "Asn", "Lys", "Lys"}, {"Ser", "Ser", "Arg", "Arg"} },
{ {"Val", "Val", "Val", "Val"}, {"Ala", "Ala", "Ala", "Ala"}, {"Asp", "Asp", "Glu", "Glu"}, {"Gly", "Gly", "Gly", "Gly"} }
};
struct Amino_Acid {
char Amino_seq[20000];
} AA_seq[3];
/* AA_seq[0]는 1약자
AA_seq[1]은 3약자
AA_seq[2]는 코돈 단위로 분리한 서열 */
// 전역변수 선언부
// 함수 선언부
void translation_codon( char *mRNAseq, int temp_i );
int find_AUG ( char *mRNAseq );
main()
{
int temp_taa, temp_AUG_slot;
char mRNA_seq[10000] = "\0";
printf("입력 예시: UUU (#주의# 코돈 입력은 반드시 대문자로 해주세요.)\n");
printf("출력 예시: %c \n", codon_table_2[0][0][0][0]);
printf("U = 0, C = 1, A = 2, G = 3\n코돈 입력\n>>> ");
scanf("%s", mRNA_seq);
printf("숫자를 입력하세요\n 0 입력: 아미노산 한 글자로 출력\n 1 입력: 아미노산 세 글자로 출력\n>>> ");
scanf("%d", &temp_taa);
temp_AUG_slot = find_AUG( mRNA_seq );
translation_codon( mRNA_seq, temp_AUG_slot );
printf("mRNA Seq. 출력\n>>> %s\n", AA_seq[2].Amino_seq);
printf("translation\n>>> %s\n", AA_seq[temp_taa].Amino_seq);
return 0;
}
void translation_codon( char *mRNAseq, int temp_i )
{
int i=0, j; // 반복문 매개변수
int temp;
int x=10, y=10, z=10; // codon 매개변수
i=temp_i;
if(temp_i > strlen(mRNAseq) ) {
printf("Error: Not found initiation code");
exit(0);
}
/* AUG를 인식하지 않으면 번역하지 않도록 하는 키
제거해도 코드의 동작에는 오류가 없다. */
while ( i<strlen(mRNAseq) )
{
if( mRNAseq[i] != '\0' )
{
x=10, y=10, z=10;
for(j = 0; j < 3 ; j++)
{
if(mRNAseq[i] == 'U') {
temp = 0;
if(j == 0) { x = temp; }
else if(j == 1) { y = temp; }
else if(j == 2) { z = temp; }
else { printf("코드에 오류가 있습니다.\n"); }
}
else if(mRNAseq[i] == 'C') {
temp = 1;
if(j == 0) { x = temp; }
else if(j == 1) { y = temp; }
else if(j == 2) { z = temp; }
else { printf("코드에 오류가 있습니다.\n"); }
}
else if(mRNAseq[i] == 'A') {
temp = 2;
if(j == 0) { x = temp; }
else if(j == 1) { y = temp; }
else if(j == 2) { z = temp; }
else { printf("코드에 오류가 있습니다.\n"); }
}
else if(mRNAseq[i] == 'G') {
temp = 3;
if(j == 0) { x = temp; }
else if(j == 1) { y = temp; }
else if(j == 2) { z = temp; }
else { printf("코드에 오류가 있습니다.\n"); }
}
else { printf("ERORR_CODE_%d잘못된 입력입니다.\n다시 입력해주십시오.\n", i); }
i++;
}
if(x>3 || y > 3 || z > 3 ) {
printf("\nERORR_CODE_123잘못된 입력입니다.\n다시 입력해주십시오.\n");
printf("%d %d %d\n", x, y, z);
}
else if( strncmp( codon_table_2[x][y][z], "stop", 4) == 0 ) {
strcat( AA_seq[2].Amino_seq, codon_table_1[x][y][z] );
strcat( AA_seq[2].Amino_seq, " \0");
break;
}
else {
strcat( AA_seq[0].Amino_seq, codon_table_2[x][y][z] );
strcat( AA_seq[0].Amino_seq, " \0");
strcat( AA_seq[1].Amino_seq, codon_table_3[x][y][z] );
strcat( AA_seq[1].Amino_seq, " \0");
strcat( AA_seq[2].Amino_seq, codon_table_1[x][y][z] );
strcat( AA_seq[2].Amino_seq, " \0");
}
}
else { break; }
}
printf("\n");
}
int find_AUG ( char *mRNAseq )
{
const char initiation_codon[4] = "AUG\0";
int i;
int AUG_slot = 0;
for( i=0; i<strlen(mRNAseq)+1; i++ ) {
if( mRNAseq != '\0' ) {
if( mRNAseq[i] == 'A' && mRNAseq[i+1] == 'U' && mRNAseq[i+2] == 'G' ){ return AUG_slot; }
else{ AUG_slot++; }
}
else {
return AUG_slot;
}
}
}'프로젝트 > 개인 프로젝트' 카테고리의 다른 글
| [간단 코드] 좌석 예약(2) (0) | 2024.01.10 |
|---|---|
| [간단 코드] 좌석 예약(1) (0) | 2024.01.04 |
| Central Dogma C프로그램(5)_개시코돈 인식 후 번역 (0) | 2022.03.30 |
| Central Dogma C프로그램(4)_임의의 서열 삽입 (0) | 2022.02.20 |
| Central Dogma C프로그램(3)_mRNA Seq. 입력 시 아미노산 서열 단순 출력 (0) | 2022.01.20 |



